데이터 엔지니어링 초보자 가이드 (A Beginner's Guide to Data Engineering)
아래 링크는 데이터 엔지니어링 초보자 가이드라는 제목으로 medium에 올라온 아주 유명한 세편짜리 글이다. 초보자 가이드다 보니 상당히 포괄적이고 개념 하나가 자세하진 않지만 정말 좋은 내용으로 채워져있다. 한번 읽어보면 데이터 엔지니어가 아니더라도 데이터를 다루는 사람이면 데이터 엔지니어링에 대한 지식이 왜 필수적인지 깨닫게 된다. 또한 데이터 엔지니어링이 무엇인지 감을 잡을 수 있다.
저자는 로버트 챙이라는 사람으로 에어비앤비에서 데이터 사이언티스트로 일하고 있다. 데이터 사이언티스트, 데이터 엔지니어 등 데이터 관련 직업을 가진 사람이라면 꼭 한번쯤 읽어봐야 한다고 생각한다. 개인적으로는 공감가는 부분도 엄청 많았다. 영어가 힘든 사람들을 위해 아래 포스팅 내용을 한국어로 요약하여 정리하고자 한다. 영어가 되는 분들은 링크로 가서 본문을 보면 훨씬 좋다.
https://medium.com/@rchang/a-beginners-guide-to-data-engineering-part-i-4227c5c457d7
A Beginner’s Guide to Data Engineering - Part 1
1. 글의 동기
나는 숙련된 데이터 사이언티스트에게 있어서 데이터 엔지니어링 스킬이 얼마나 중요한지 전달하고자 한다. 데이터로부터 중요한 가치를 끌어내기 위해서는 우선 정돈된 데이터 인프라와 데이터 웨어하우스가 전제되어야 한다. 따라서 데이터 사이언티스트는 필수적으로 데이터 엔지니어링에 대한 지식을 갖추고 있어야 한다. 하지만 현재의 데이터 엔지니어링에 교육에는 많은 한계가 있다.
2. 첫 번째 직장
나는 졸업 후 작은 스타트업에 데이터 사이언티스트로 취직을 했다. 첫 커리어를 시작하며 나는 데이터로 부터 멋진 인사이트를 발굴하기를 기대했다. 하지만 그런 기회는 주어지지 않았다. 내가 회사에서 마주하게된 데이터들은 전처리가 완료된 깔끔한 데이터와는 거리가 먼, 야생의 로우 데이터였다. 많은 데이터 사이언티스트들이 그들의 커리어에서 비슷한 여정을 겪을 것이다. 그들에게 최선의 방법은 이 현실을 빨리 깨닫고 적응하는 것이다. 나는 머신이 생성한 수많은 로그나 타임스탬프와 씨름하고 SQL을 배우며 천천히 데이터 엔지니어링을 익혀왔다.
3. 분석을 위한 계층구조 (The Hierarchy of Analytics)
나는 데이터 사이언티스트의 로망과 현실의 괴리를 지적하는 글 중에 Monica Rogati가 AI를 도입하고자 혈안이 된 회사들에게 날리는 경고의 글(https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007)을 인상깊게 읽었다.
AI는 욕구의 피라미드의 꼭대기에 있다. 물론 자아실현(AI)은 훌륭하다. 하지만 당신은먼저 음식, 물, 그리고 주거지(데이터 수집, 데이터 인프라)가 필요하다.
모니카의 말대로 회사들이 데이터로부터 유용한 정보를 얻거나 제품을 생산하기 위해서는 그림에 있는 아래 층의 필수 레이어가 먼저 충족되어야 한다.
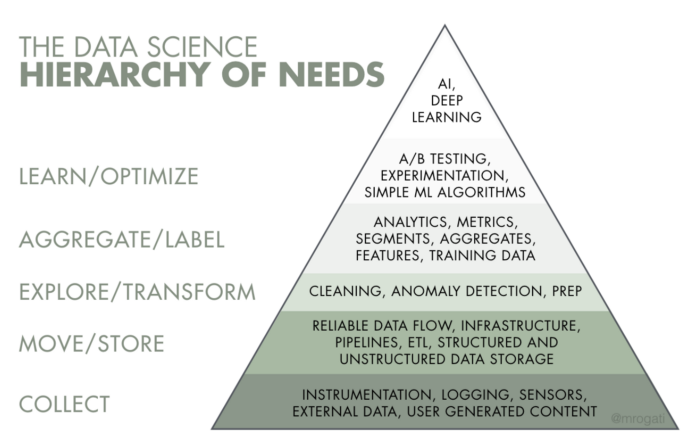
출처: Monica Rogati’s Medium post, The AI Hierarchy of Needs
하지만 그 어떤 코스에서도 학생들에게 테이블 스키마를 알맞게 디자인 하거나, 데이터 파이프라인을 만드는 법을 제대로 가르치지 않는다. 나는 데이터 사이언티스라면 데이터 엔지니어링에 대해 일정 수준의 지식을 갖춰야 한다고 생각한다.
4. 데이터 웨어하우스 만들기
일단 데이터 엔지니어링이란 무엇일까? 에어플로우의 원저자 Maxime Beauchemin는 그의 포스팅(https://www.freecodecamp.org/news/the-rise-of-the-data-engineer-91be18f1e603)에 데이터 엔지니어링을 정의하였다.
데이터 엔지니어링이란 소프트웨어 엔지니어링에서 많은 요소를 가져온 비지니스 인텔리전스와 데이터 웨어하우징의 슈퍼셋이다. 또한 데이터 엔지니어링은 빅데이터라 불리는 영역(분산 시스템, 하둡 에코시스템, 스트림 프로세싱)을 포함한다.
데이터 엔지니어가 하는 많은 중요한 일들 중에 필수적인 스킬은 데이터 웨어하우스를 디자인 및 설계하고 유지보수하는 일이다. 데이터 웨어하우스란 원본 데이터가 쿼리 가능한 형태로 변형되어 저장되어 있는 곳이다. 웨어하우스가 없다면 데이터 사이언스를 수행하기 위해 아주 많은 비용이 들 것이다.
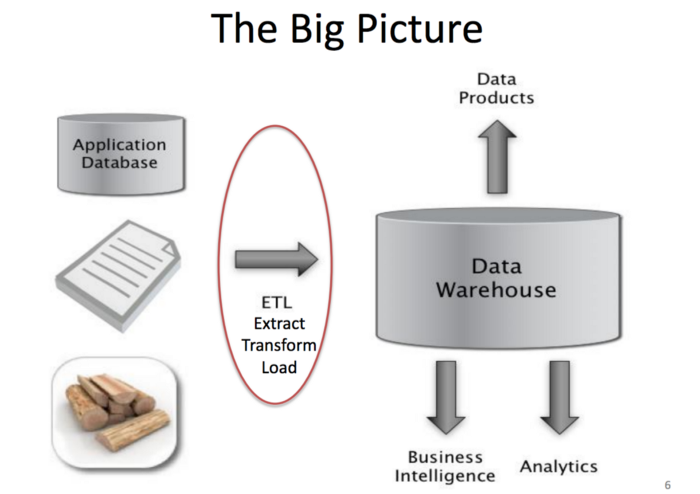
출처: Jeff Hammerbacher’s slide from UC Berkeley CS 194 course
5. ETL: Extract, Transform, and Load
데이터 웨어하우스의 설계는 ETL(Extract, Transform, Load)이라 불리는 공통적인 패턴을 따른다. 대부분의 데이터 파이프라인 디자인은 이 세가지 스텝으로 이루어져있다. 한마디로 ETL이란 원본 데이터가 어떻게 분석이 가능한 데이터로 변형되는지 보여주는 청사진이다.
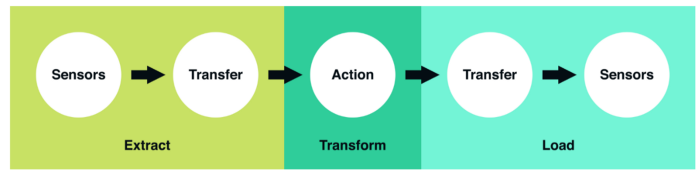
출처: Vineet Goel, Why Robinhood uses Airflow? Medium Post
1) Extract
Extract 단계는 업스트림 데이터 소스가 데이터를 생성하기를 기다리는 단계다. 데이터가 생성되면 앞으로의 단계를 위해 소스에서부터 중간 목적지로 데이터를 운반한다.
2) Transform
Transform 단계는 ETL의 핵심이다. 이 단계에서 우리는 원본 데이터를 분석 가능한 데이터로 만들기 위한 필터링, 그루핑, 어그리게이션과 같은 작업을 실행한다.
3) Load
마지막으로 Load 단계에서는 처리된 데이터를 목적지로 운반한다. 목적지는 사용자일 수도 있고 다른 ETL 태스크일 수도 있다.
6. Choosing ETL Frameworks
많은 회사들이 ETL을 설계의 난관을 보다 수월하게 해결하기 위한 프레임워크를 설계했다. 특히 배치 데이터 프로세싱에서 주로 쓰이는 프레임워크는 링크드인의 아즈카반, 스포티파이의 루이지, 핀터레스트의 핀볼, 에어비앤비의 에어플로우 등이 있다. 각 프레임워크는 서로 다른 장단점을 가지고 있다. 프레임워크 선정에 있어서 중요한 필수적으로 고려해야 할 요소들은 다음과 같다.
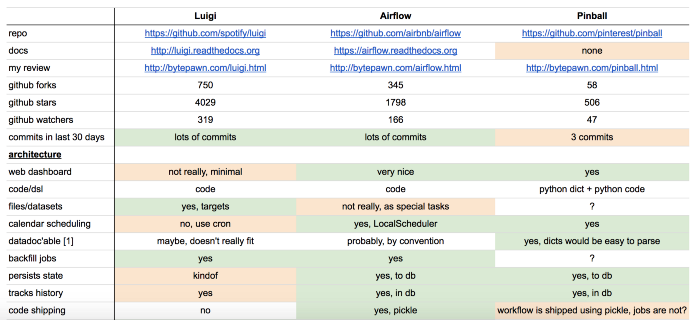
출처: Marton Trencseni’s comparison between Luigi, Airflow, and Pinball
1) Configuration
ETL은 복잡하기 때문에 보다 간결하게 표현할 수 있는 방법이 필요하다. 따라서 프레임워크에서 ETL을 어떻게 표현하는지(코드, 언어, UI 등) 고려해야 한다. 최근에는 코드로 ETL을 나타내는 것이 일반적이다.
2) UI, Monitoring, Alerts
오래 걸리는 배치 프로세싱은 불가피하게 에러를 마주할 수밖에 없다. 따라서 해당 태스크의 진행을 트래킹하는데에 모니터링과 알람이 중요하다. 프레임워크가 해당 기능; 모니터링과 알람을 얼마나 잘 제공해주는 주의깊게 봐야한다.
3) Backfilling
우리는 가끔 과거의 데이터를 다시 처리해야 할 때가 있다. 하지만 이를 위해 과도한 오버헤드가 생기는 것은 누구나 원치 않을 것이다. 프레임워크가 백필링을 얼마나 효율적으로 지원해주는지 따져보는 것은 중요한 문제다.
7. SQL- v.s. JVM-Centric ETL
회사에 따라 ETL을 관리하는데 서로 다른 툴과 프레임워크를 쓴다. 이 패러다임을 크게 나누자면 두 가지로 나눌 수 있다. 첫 번째는 자바 중심의 ETL이고 두 번째는 SQL 중심의 ETL이다.
1) JVM-centric ETL
JVM 중심의 ETL은 JVM기반의 언어로 쓰여져 있다. 이 경우에는 테스팅이나 사용자 정의 함수(UDFs)가 JVM 기반의 언어로 작성되기 때문에 좀 더 수월하다는 장점이 있다.
2) SQL-centric ETL
SQL 중심의 ETL은 SQL, Presto, Hive와 같은 언어로 쓰여져 있다. 테스팅을 하거나 사용자 정의함수를 작성하기 위해서는 SQL외에 다른 언어를 써야하므로 번거롭다.
나는 SQL중심의 ETL을 선호한다. 왜냐하면 자바 등의 언어를 배우는 것보다 SQL을 배우는 것이 훨씬 쉽기 때문이다.
파트 1 번역은 여기까지! 파트 2랑 파트 3도 천천히 올릴 예정이다.
댓글
댓글 쓰기